What is this Dataset?
Transformers Concept Net is a collection of latent concepts derived from five Transformer Models: BERT-cased, RoBERTa, XLNet, XLM-RoBERTa, and ALBERT. This dataset was created by clustering contextualized word representations from these models and then annotating the resulting clusters with the help of ChatGPT. The goal of the dataset is to improve the understanding and analysis of deep transformer models. We utilized a subset of the WMT News 2018 dataset consisting of 250K sentences as our base for concept discovery, and extract 600 concepts per layer for each of the five models.
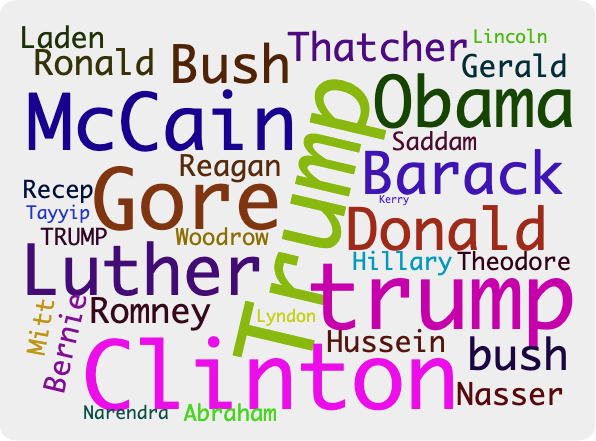
Political Figures: Albert Layer 9

Geographic Locations in California: Bert Layer 12